legisCrawler: An Automation Webcrawling Toolkit for Retrieving Taiwan Parliamentary Questions 🛠️🧰
![]()
![]()
An automation web crawling framework for retrieving parliamentary questions on The Website of Taiwan Legislative Yuan 立法院 (https://lis.ly.gov.tw/) based on Selenium library in Python and Chrome browser.

Requirements
- python>=3.7.3 🐍
- pip>=19.2
- numpy=1.16.2
- pandas=0.24.2
- matplotlib=3.0.3
- selenium
- webdriver-manager
Instruction
-
Need to install Anaconda Navigator and Python>=3.7.3 beforehand. And then, open the terminal and download
legisCrawlerrepository by usinggit clone. -
About how to use git and Github, please have a look at this Tutorial for Beginners.
git clone git@github.com:davidycliao/legisCrawler.git
- Copy the commands below and paste them into the terminal:
# Change the directory by typing `cd` command once `legisCrawler` repository is downloaded.
cd legisCrawler
# Create the enviroment by using conda and name the enviroment `legisCrawler`.
conda create -n legisCrawler python=3.7
# Activate the pre-named enviroment.
conda activate legisCrawler
# Install the dependencies from `requirements.txt` using `pip` methond.
pip install -r requirements.txt
- Run
legisCrawlerin your Python:
# Note: you need to run it in the terminal where you activated the enviroment.
python legisCrawler.py
- When legisCrawler is running, you will be asked which term (2nd - 10th) you would like to scrape (please, type any single digit from 2 to 10). Then legisCrawler will automatically create a folder to restore the retrieval of parliamentary questions by individual member.
Workflow
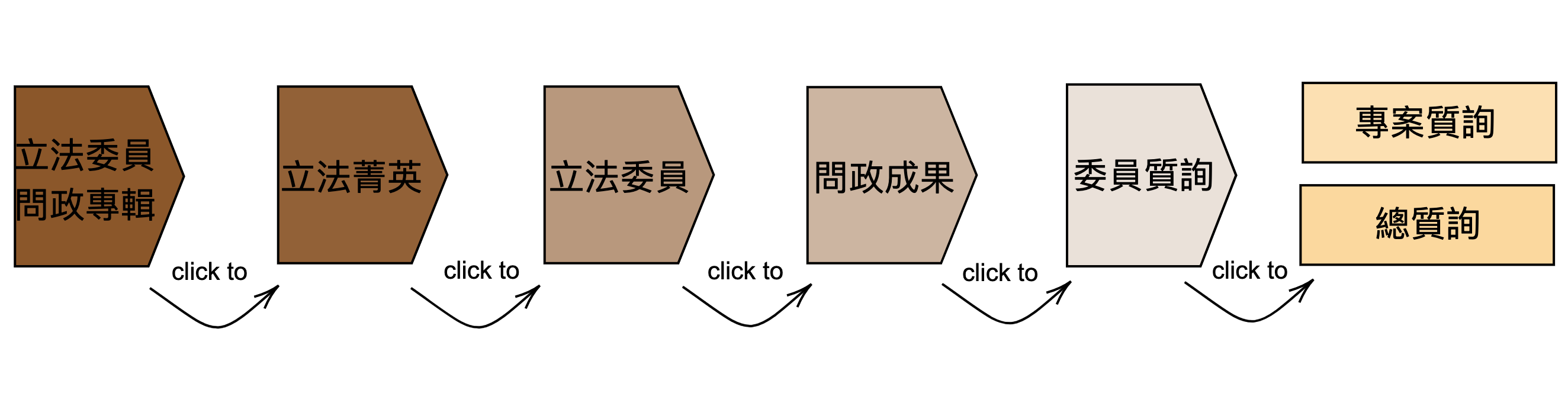
What legisCrawler Scrapes
This designed crawler automatically webscrapes the parliamentary questions (專案質詢) from The Website of Legislative Yuan, including a bunch of information with regards to the topic, keywords and the type. An additional module for getting a corpus of grand parliamentary debates (總質詢) is in progress and will be available soon.
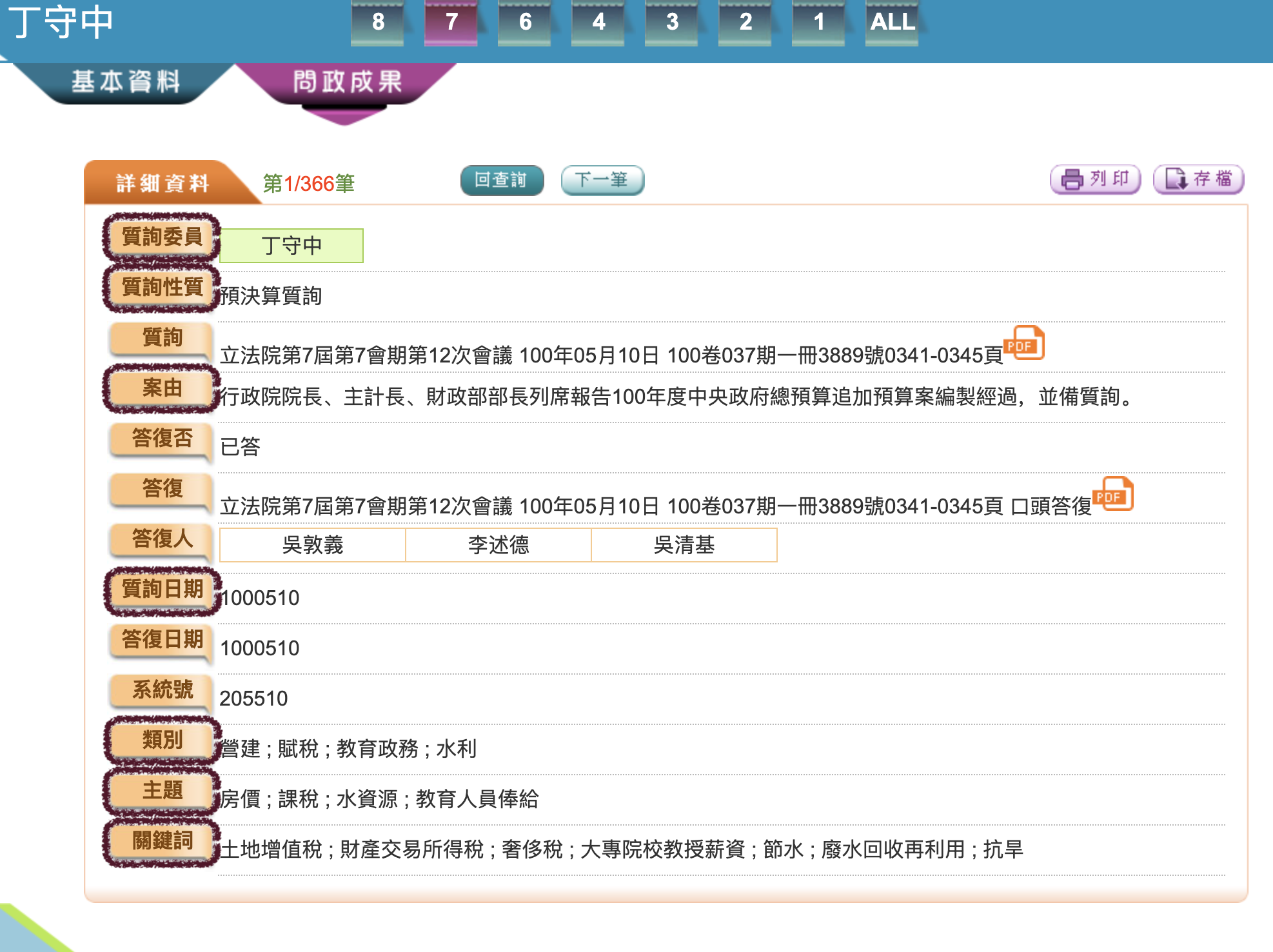
Note
If there’s anything you need about running legisCrawler, please don’t hesitate to post a message in Discussion 📣. 如果有任何需要幫忙的地方,歡迎到留言在發問區,或者email 給我。我會抽空來幫忙解決問題!
Cite
For citing this work, you can refer to the present GitHub project. For example, with BibTeX:
@misc{legisCrawler,
howpublished = {\url{https://github.com/davidycliao/legisCrawler}},
title = {An Automation Webcrawling Toolkit for Retrieving Taiwan Parliamentary Questions},
author = {David Yen-Chieh Liao and Calvin Yu-Ceng Liao},
publisher = {GitHub},
year = {2021}
}